INTRO
Nei corsi di Informatica/Sistemi delle scuole medie superiori solitamente si trattano argomenti relativi ai Sistemi Operativi, come concorrenza, task, sincronizzazione. Per quanto ho potuto vedere, non ci sono poi implementazioni di tecniche adatte allambiente Microsoft. Di solito si trova "minestra riscaldata" di qualche timido sorgente UNIX riproposto, oppure esempi in (pseudo) Concurrent Pascal ma poi non applicabile nella pratica. Altri tentano la migrazione a Linux dove ripropongono esempi banali recuperati dai loro testi universitari dei bei tempi. Non lo trovo giusto:
- il 90% dei PC nel mondo è Windows (la cosa può piacere o meno ma è così... non piace neanche a me...)
- Windows ha ottime funzioni per il multi-tasking ed il threading
- i ragazzi a casa hanno PC e Windows
Vediamo allora come sia possibile creare applicazioni con più threads, tralasciando gli aspetti legati alla creazione e gestione dei processi.
Precisiamo fin dora che col termine Windows itendiamo tutta al famiglia di S.O. derivati da NT 4.0: useremo il termine Microsoft "Win32" per designare tali sistemi operativi a 32 bit, anche se quanto verrà esposto vale anche per le versioni a 64 bit (quanto nellarticolo è stato provato anche su macchina Xeon 64 bit col nuovo Visual Studio 2005 a 64 bit).
Multitasking, UNIX, Win32 e Threads
Prima di addentrarci nel nostro esempio, ci pare doveroso dare qualche cenno alla storia ed alla teoria che costituisce il background teorico dellarticolo, senza voler spiegare tutta la teoria dei Sistemi Operativi (dora in avanti SO per brevità), ben spiegata in [1,5].
In ambiente Unix, dove è nato il concetto di SO multi-programmato, si usa il termine mutitasking, per denotare la capacità che un SO può avere di eseguire diversi compiti (task) contemporaneamente. Con lavverbio contemporaneamente si intende solitamente che il computer può portare avanti più attività (programmi, calcoli, elaborazioni etc.) in parallelo, senza dover aspettare la fine del programma corrente per poter eseguire un altro compito.
Precisiamo ulteriormente lavverbio: contemporaneamente può sottintendere sia un parallelismo effettivo (fisico, dove più processori effettivamente elaborano più istruzioni), sia un parallelismo logico, dove gli utenti vedono procedere i propri programmi come se il computer fosse contemporaneamente dedicato al singolo task.
Ciò è nato per ottimizzare i costi, non certo per motivi teorici particolari. Negli anni 60 un mainframe costava milioni di dollari, ed aspettare la fine di un task per poter elaborare i lavori di un altro utente era inaccettabile dal punto di vista dei costi. La teoria ha quindi elaborato un concetto: lefficienza dei SO .
Spesso un task era fermo, col processore in idle o in polling in attesa di input utente o dati da una periferica lenta. Perché non utilizzare in modo più efficiente questi tempi morti? Si poteva quindi sospendere il task in attesa dei dati e passare ad elaborare il prossimo task, almeno per un po di tempo, finché i dati del primo non fossero pronti. In questo modo il processore era effettivamente utilizzato per compiti produttivi (efficienza). Ovviamente le implementazioni richiesero lintroduzione di altri termini:
- un programma che si occupasse di gestire queste "sospensioni" e "riavvii", (lo scheduler),
- una architettura in grado di salvare tutti i dati necessari al funzionamento di ogni task, ossia le sue variabili, i flags ed i registri. Linsieme di questi dati compone lo stato di un task, detto anche contesto o context; mentre lazione svolta dal sistema operativo prende il nome di context switching
- stabilire i quanti minimi di tempo dedicati ad un singolo task, i time-slice
- la sospensione forzata di un task alla fine dei suo time-slice (preemption).
Con il termine context switching intendiamo la sequenza di operazioni, sia software (da parte dello scheduler e di altri moduli del kernel), sia hardware, che salvano lo stato di un processo che ha finito il suo time-slice e la sequenza simmetrica di operazioni che caricano registri, flag, variabili del prossimo processo che da ready sta per passare a run.
Parliamo quindi di processi caricati in memoria, che possono essere in uno solo dei seguenti stati:
- run: il processo è attivo e hai tutto il processore per sé, diremmo che il Program Counter punta alla sua area codice
- ready: al processo manca solo il tempo di CPU: ma ha già tutte le risorse allocate e i dati necessari sono arrivati e/o sono stati già spediti alle periferiche
- wait: il processo è in attesa di dati da periferiche o di risorse hardware non disponibili al momento
Precisiamo che esiste una leggera differenza concettuale fra task e processo, anche se in ambiente Unix tutti adottano la convenzione che i due termini siano esattamente sovrapponibili e sinonimi:
- un task è un lavoro, una attività da eseguire che usa tempo di CPU, ed è un termine generico
- un processo è una sequenza di istruzioni caricate in memoria, che usa tempo di CPU, ha dei propri valori per i registri ed i flags, ha il program counter che punta al suo codice, ha un suo stack (ed uno heap) ed una sua area dati, ed ha un suo percorso di esecuzione (execution path).
In ambiente Unix è possibile per un processo creare processi "figli" che operano in modo indipendente dal "padre", anche se tipicamente ne condividono il codice. Tali istruzione (syscall, per essere precisi) sono le fork.
In ambiente Win32 non esistono tali primitive di fork, ma esistono funzionalità analoghe: CreateProcess(), che ha la bellezza di dieci parametri [4]. Portare quindi un sorgente Unix, scritto facendo uso di fork e processi, sotto Win32 non è sempre agevole.
La pesantezza in termini di cicli di CPU, ma soprattutto la maggior complessità programmativa dei processi sotto Win32, spesso consiglia di passare ad una soluzione più snella: i Thread.
Thread significa "trama" /"fibra" e designa un percorso di esecuzione parallela (execution path).
Ogni thread condivide con altri thread area dati, heap e "ambiente", ma ha (ovviamente) 4 elementi propri: uno stack, un Program Counter, un Instruction Pointer, un set di registri, questi ultimi indispensabili per permettere un execution path indipendente per ogni thread.
Nella letteratura Microsoft ogni eseguibile, anche se singolo, è costituito da almeno un thread. Il thread che nasce per primo è detto main thread, ed è esso che eventualmente crea thread figli, diremmo meglio fratelli, perché condividono le risorse del main thread.
Per completare questo breve excursus sulla programmazione multi-thread, citiamo altri aspetti:
- anche sotto Unix esistono i thread, grazie a delle librerie POSIX, detti pthread che poi sono state ri-riportati anche sotto Win32.
- E possibile utilizzare un modello "ibrido" che usi sia thread che processi, la mutua interazione è complicata dalla presenza di tipi "C" non intercambiabili e non "castabili", oltre che utlizzare logiche diverse.
- Quando si programma in modo concorrente, non esiste del flusso sequenziale nellesecuzione del programma e di accesso ai dati. Questo significa che il programmatore non sa mai in anticipo quando una parte di codice va effettivamente in esecuzione, né in che ordine una variabile condivisa viene letta e/o modificata da uno dei task.
Non approfondiremo ancora altri aspetti, e rimandiamo ai testi citati in bibliografia.
Perché usare i thread
La conoscenza dei thread permette ai programmatori di scrivere programmi in genere meno complessi, perché un problema complesso può essere meglio risolto spezzandolo in moduli di esecuzione separati. Threadando un programma, di solito si migliora la "granularità" di esecuzione e si ottiene un miglior utilizzo del tempo di CPU (un thread inattivo non usa CPU), e, se la macchina è multi-processore, più thread, per esempio di calcolo, possono essere eseguiti su più processori diversi aumentando il parallelismo dellelaborazione.
Un altro impiego può essere un a applicazione server - http server o DBMS. Un thread principale riceve le richieste, crea dei thread di gestione a cui delega il carico elaborativo, pronto a gestire nuove chiamate. In questo caso la priorità di elaborazione viene data data al main thread, che quindi può passare subito ad accettare nuove richieste, mentre tocca ai thread "figli" , con priorità più bassa, elaborare le richeste.
Lapproccio a thread, anziché a processi, in genere è più "leggero" per il Sistema Operativo poiché, fra le altre cose, richiede meno lavoro per switchare il contesto.
Anche la sincronizzazione è più semplice e la condivisione dei dati è meno complicata che condividere memoria fra processi separati.
Lapproccio a thread è inoltre indispensabile quando si devono scrivere programmi che hanno a che fare con lHW, per esempio con la seriale: anni fa era sufficiente modificare la tabella degli interrupt: appena viene ricevuto un carattere, il µp viene invocato lInterrupt Handler che in modo asincrono gestiva la ricezione mentre il programma principale "ascoltava" i comandi dellutente.
In Win32 la gestione degli Interrupt tramite user-code non è più ammessa: lalternativa è scrivere Interrupt Handler o Driver col Driver Development Kit (DDK di Microsoft), spesso uno sforzo esagerato per il normale programmatore applicativo.
Utilizzando un thread principale e 2 thread secondari di ricezione/trasmissione si ottiene il risultato voluto senza uno sforzo programmativo eccessivo. Lo stesso dicasi per la parallela, la rete, lI/O in genere, in tutti quei casi dove comunque la latenza non è critica.
Ricordiamo infine che concetti come "blocco critico" e "blocco individuale" "race condition" sono "in agguato" anche qui.
Una ultima nota sul concetto di efficienza: se usiamo i thread, utilizziamo meglio la CPU per eseguire ALTRI compiti mentre uno o più thread sono in attesa di dati o eventi HW (efficienza complessiva). Daltro canto un singolo programma è sicuramente piu lento se realizzato con i thread, rispetto ad una versione che p.es. effettua il polling "bruciando" cicli di CPU (efficienza locale), ma non perdendo tempo utile nel context switching.
Logica di funzionamento del programma
In questo articolo vedremo passo passo come creare due piccole applicazione in C, senza MFC utilizzando il buon vecchio e caro Microsoft Visual C++ 6. Creeremo dapprima una piccola applicazione console per "familiarizzare" coi thread, per poi passare ad una applicazione grafica con un po più di funzionalità.
Il primo programma semplicemente scatena due thread che stampano a video un messaggio, e vedremo qualche aspetto legato alla coesistenza di più thread.
Nel secondo Il programma principale creerà una serie di threads ognuno dei quali muoverà un oggetto grafico calcolando in modo autonomo la posizione.
Lapplicazione, una volta lanciata, inizializzerà i thread e li farà partire, killandoli in uscita. Ogni thread sarà innescato da un proprio timer, per far muovere gli oggetti in modo finito: senza timer si muoverebbero alla velocità che la CPU permette, ossia con milioni di spostamenti al secondo e non visualizzeremmo nulla di apprezzabile.
I timer saranno globali alla applicazione, e sospenderanno o faranno partire i thread. In altri casi può essere sufficiente utilizzare la funzione Sleep() che fa passare i thread in wait e spetterà allo scheduler risvegliarli. Ho preferito sospendere e risvegliare i thread esplicitamente con nostre chiamate per mostrare sia luso dei timer, sia soprattutto luso delle primitive di SuspendThread() e ResumeThread().
La sincronizzazione inter-thread non ha molta importanza in questi due esempi, anche se essa riveste una importanza fondamentale nella progettazione di programmi multi-thread reali.
Per poter implementare quanto richiesto, ci servirà visualizzare alcuni di oggetti a video. Per limitare la complessità saranno semplici rettangoli colorati, uno per ogni thread.
Per seguire correttamente lesempio sono necessari i pre-requisiti seguenti:
- Microsoft Visual C++ installato correttamente
- Conoscenza dellambiente di sviluppo
- Conoscenza del principali API di windows per le applicazioni GUI e dei Timer
API per il multithreading
Tutti i sistemi di sviluppo che si rifanno al modello win32 contengono una collezione molto ricca di primitive dedicate alle gestione dei thread.
Vedremo alcune delle principali funzioni di Windows per gestire il mutithreading: Ne daremo solo una veloce panoramica (rimandiamo bibliografia (1) ) e passeremo alla parte implementativa.
Per la creazione dei thread, Windows fornisce la funzione "CreateThread()". Tale funzione crea un thread con alcuni parametri caratteristici, quali la routine che costituisce il corpo del thread, la dimensione dello stack, i parametri di inizializzazione.
Vediamo nel dettaglio il prototipo e i parametri da passare alla funzione:
HANDLE CreateThread(
LPSECURITY_ATTRIBUTES lpThreadAttributes ,
// pointer to security attributes
DWORD dwStackSize , // initial thread stack size
LPTHREAD_START_ROUTINE lpStartAddress ,
// pointer to thread function
LPVOID lpParameter , // argument for new thread
DWORD dwCreationFlags , // creation flags
LPDWORD lpThreadId // pointer to receive thread ID
);
lpThreadAttributes: non lo utilizziamo, sarà NULL. [3] È comunque lindirizzo delle impostazioni sugli attributi di sicurezza con cui il nuovo thread viene eseguito.
dwStackSize: dimensione dello stack. Ogni thread ha un proprio stack: il valore 0 significa dimensione per default 1 MB.
lpStartAddress: indirizzo della funzione di inzializzazione del thread. In essa effettueremo le necessarie inzializzazioni e/o allocazioni. Il prototipo deve essere:
DWORD WINAPI ThreadProc(LPVOID lpParameter);
Al posto di ThreadProc metteremo nome della nostra funzione. Il parametro sarà lindirizzo di una struttura necessaria per inizializzare correttamente il thread. Questo valore è un puntatore generico con lo stesso valore che abbiamo specificato in fase di creazione nel parametro lpParameter della funzione CreateThread().
La logica è la seguente: il main thread deve poter parametrizzare ogni singolo thread, nel caso che la funzione che lo implementa sia la stessa .Daltro canto il frammento di codice che implementa il corpo del thread deve essere chiamato direttamente dallo scheduler e non può avere un numero qualsiasi di parametri come se fosse una nostra funzione. Detto in altro modo lo scheduler deve fare lo stesso numero di PUSH. Quindi il corpo del thread riceve un puntatore generico che verrà castato al tipo richiesto.
In fase di creazione passiamo un puntatore a dati / strutture del main thread, Windows memorizza tale riferimento e lo passa al thread quando esso va in esecuzione. Non sempre infatti il thread ha la visibilità sulle strutture dati visibili al main thread, oppure il thread è scritto in un altro file e non vogliamo avere variabili globali e/o dichiarazioni extern.
lpParameter: vedi sopra.
dwCreationFlags: flag di inizializzazione: 0 o CREATE_SUSPENDED. Se zero il thread va subito in esecuzione.
lpThreadId: indirizzo di un long che in uscita conterrà lID del thread. In tal modo windows può passare lID del nuovo thread al main thread.
Ogni thread è quindi identificabile tramite due valori:
- lhandle ritornato da CreateThread()
- lID contenuto nel long puntato dal parametro lpThreadId.
DWORD SuspendThread(
HANDLE hThread // handle to the thread
);
la funzione sospende il thread specificato attraverso il suo handle: andrà nella coda dei processi in wait.
BOOL TerminateThread(
HANDLE hThread , // handle to the thread
DWORD dwExitCode // exit code for the thread
);
la funzione termina il thread specificato con handle; si può passare alla funzione. un valore intero, dwExitCode, che il thread può analizzare per decidere come "morire".
In apposite globali terremo traccia dei nostri thread per poterli manipolare e killare in uscita. Al solito Windows eseguirebbe per noi il cleanup automatico di tutto ciò che lasciamo aperto e allocato, ma "you must be a good citizien" e quindi de-allochiamo e chiudiamo quanto allocato e aperto.
Thread, calback e Start routine di thread
Abbiamo detto "creazione", ma teniamo presente che il codice che verrà eseguito è contenuto nella funzione puntata da lpStartAddress e che tale codice verrà eseguito una sola volta, a meno che contenga del loop.
Questo comportamento è ben diverso per esempio dalle funzioni innescate dai timer, dove la callback viene chiamata ogni volta che il timer "fires up".
Una volta che il/i thread sono in esecuzione, il programma principale deve solo aspettare che i thread "muoiano". Ciò avviene quando lesecuzione raggiunge lultima riga della funzione puntata da lpStartAddress. In alternativa un thread può "suicidarsi" invocando ExitThread. Qualora non lo facesse, Windows chiamerebbe implicitamente ExitThread quando il main thread termina. La documentazione ufficiale MSDN consiglia di chiamare comuque sempre esplicitamente ExitThread se si vuole interrompere un thread durante lelaborazione.
In altri casi il main thread, oppure un altro thread, può sospendere o killare un thread tramite le apposite funzioni SuspendThread e TerminateThread.
Lesempio console: PASSI DA SEGUIRE
1) Creiamo il solito progetto .DSP, una Win32 Console Application, con un nome adatto: ThreadSampleInConsole. Al solito lasciamoci guidare dal Wizard creando un progetto stile "Hello World."
Nel file principale dichiariamo le variabili utili per la creazione del primo thread:
#define MAX 2 unsigned int Param=1; DWORD ID1; HANDLE arh[MAX];
Abbiamo definito un parametro di valore 1, per contrassegnare il primo thread. Tale valore verrà passato al thread per distinguerlo dal 2° thread.
Si noti larray di HANDLE, infatti avremo più di un thread.
Scriviamo la funzione di creazione del primo thread:
CreateThread(NULL,0,ThreadProc,&Param,0,&ID1);
2) Creiamo anche la vera funzione di threading, che nel nostro esempio banalmente scrive un po di numeri.
DWORD WINAPI ThreadProc( LPVOID lpParameter //thread data)
{
int * pn=(int*)lpParameter;
int i;
for(i=0;i<100;i++)
printf("Thread numero %d %d\n",*pn,i);
return 0;
}
Poichè è un puntatore generico, è necessario effetture il cast al tipo voluto: nel nostro caso forziamo la conversione a puntatore ad intero (int*) per poi poter ricavare il valore numerico del numero di thread.
N.B.: tale numero non è il ThreadID delle API di windows, è solo un valore di esempio.
Complessivamente avremo:
#include "stdafx.h"
#define MAX 2
DWORD WINAPI ThreadProc( LPVOID lpParameter)
{
int * pn=(int*)lpParameter;
int i;
for(i=0;i<10;i++)
printf("Thread numero %d %d\n",*pn,i);
return 0;
}
int main(int argc, char* argv[])
{
int i;
unsigned int Param=1;
DWORD ID1;
HANDLE arh[MAX];
arh[0] = CreateThread(NULL,0,ThreadProc,&Param,0,&ID1);
printf("Hello World!\n");
printf("\nmain ended");
return 0;
}
Proviamo a compilare: NON compila!
3) Aggiungiamo gli header necessari: il Wizard ha creato #include customizzato per console, quindi ha inserito nel file stdafx.h solo "stdio.h". Aggiungiamo quindi gli header tipici delle applicazioni Windows e per la gestione della console (getch()):
#include "stdafx.h" #include "WINDOWS.h" #include "conio.h"
Ora compila.
4) Completiamo il codice creando il secondo thread semplicemente per copia/incolla:
DWORD ID2; Param = 2; arh[1] = CreateThread(NULL,0,ThreadProc,&Param,0,&ID2);
abbiamo aggiunto un DWORD destinato a contenere lid del 2° thread ed abbiamo incrementato Param. Poiché un thread usa risorse, è al solito buona norma rilasciarle. Essendo handle è suffciente chiamare CloseHandle: Windows si occuperà di capire che è un riferimento ad un thread e quindi a rilasciare tutto quellinsieme di risorse, buffer, liste linkate e riferimenti connessi ai due thread. Aggiungiamo quindi in fondo al listato:
for(i=0;i<MAX;i++)
CloseHandle(arh[i]);
printf("\nmain ended\n");
getch();
return 0;
5) Lanciamo e vediamo loutput a video:
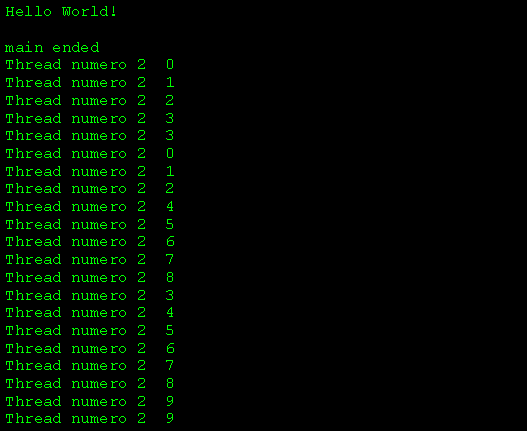
Notiamo subito 3 cose:
- il main thread ha già eseguito le sue printf ben prima che i due thread siano terminati, anche se la printf del messaggio "hello Word" nel main è dopo la creazione dei thread..
- La funzione CloseHandle notifica a Windows che i thread possono essere rilasciati ma NON termina i thread. Infatti per scelta progettuale un thread termina il suo compito al "return" del suo body, a meno che sia terminato da altri thread o si termini dal solo. In definitiva lo scheduler lo rimuove dalla lista dei task "vivi" solo dopo aver avuto un valore di ritorno.
- Appare sempre "thread numero 2"! E normale: per definizione noi abbiamo inizializzato param a 1, poi creato il thread 1, poi param è passato a due e abbiamo creato il 2° thread. Poiché param è passato per indirizzo, il thread 1 ed il 2 usano la stessa area di memoria. Quindi il thread 1 passa in esecuzione (quando lo scheduler decide che "è ora") e usa il valore corrente che può essere stato modificato dalla f. di creazione del 2° thread.
Oss: quanto evidenziato nel punto 6-c è noto come corsa critica (race condition): "si definisce corsa critica una situazione in cui il valore di una variabile dipende dallordine (casuale) in cui più processi o thread la settano/modificano"
6) Per evitare quindi la corsa critica, modifichiamo leggermente il codice:
unsigned int Param=1; arh[0] = CreateThread(NULL,0,ThreadProc,&Param,0,&ID1); unsigned int Param2=2; DWORD ID2; arh[1] = CreateThread(NULL,0,ThreadProc,&Param2,0,&ID2);
Rilanciamo e analizziamo loutput:
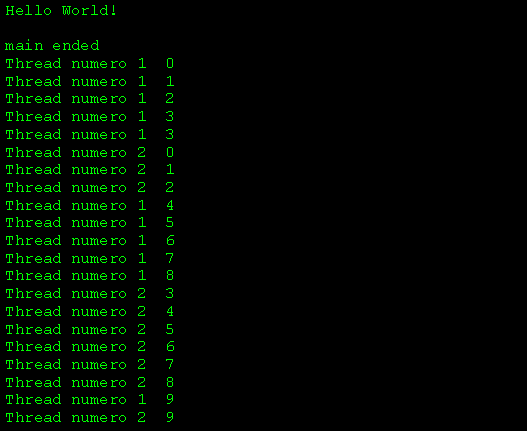
(OSS.: A causa della natura aleatoria della esecuzione dei thread regolati dalla logica e dai tempi dello scheduler, in dipendenza anche dellHW sottostante, a video potreste vedere un output diverso)
Ora il numero di thread è corretto. Ma notiamo ancora un problema:
appare due volte (ribadiamo: nel nostro caso):
![]()
Vediamo di capire perché.
I due thread sicuramente eseguono, e ne abiamo conferma tracciando step by step: la variabile i assume il valore 3. Non è quindi "colpa" del codice.
La spiegazione va ricercata nelle librerie standard "C": printf non è né rietrante né thread-safe. Le venerande librerie standard spesso utilizzano buffer condivisi o flag ed è appunto quello che succede nel nostro caso:
- il thread 1 comincia a"scrivere" o meglio la printf forma la stringa usando la stringa di formato e i valori degli argomenti in un buffer temporaneo
- lo scheduler lo interrompe e parte il thread 2 che comincia a preparare loutput usando lo stesso buffer!
- Gli stati di I/O stanno ancora lavorando sullo stesso buffer e usano gli stessi flag che (probabilmente!) il thread 2 resetta dando luogo ad una ulteriore stampa.
7) Rendiamo il progetto "thread-safe". Con un rapido colpo di Help sulla funzione printf rileviamo che:
...
Libraries
|
LIBC.LIB |
Single thread static library, retail version |
|
LIBCMT.LIB |
Multithread static library, retail version |
|
MSVCRT.LIB |
Import library for MSVCRT.DLL, retail version |
Nelle opzioni del progetto modifichiamo quindi le librerie LIBC.LIB in LIBCMT.LIB:
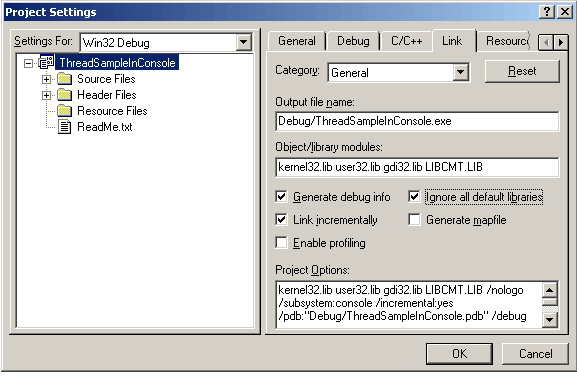
Si noti che abbiamo dovuto settare anche "Ignore all default libraries".
Un metodo più "pulito" è utlizzare lo switch del compilatore "/MT" (multithread) nel seguente modo:
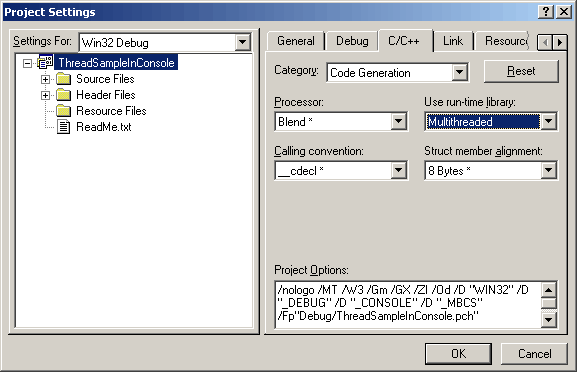
Se ora lanciamo il programma, sia in debug che da linea di comando, funziona correttamente.
Lesempio grafico: PASSI DA SEGUIRE
1) Creiamo il solito progetto .DSP, una Win32 Application, con un nome adatto: ThreadsSample. Al solito lasciamoci guidare dal Wizard creando un progetto stile "Hello World". (Si veda altri articoli sul sito su come creare una piccola applicazione win32 customizzata a partire da "Hello World").
Creiamo un file Threads.cpp e relativo header file. Al suo interno scriviamo la funzione di creazione dei nostri thread: BuildOurThreads() e la sua simmetrica ReleaseOurThreads().
2) Creiamo anche la vera funzione di threading. Per ora sono tutte funzioni vuote e avremo:
void BuildOurThreads(HWND hWnd)
{
}
void ReleaseOurThreads(void)
{
}
DWORD WINAPI ThreadProc( LPVOID lpParameter //thread data)
{
return 0
}
3) Poiché vogliamo gestire due thread e ognuno controlla un oggetto grafico, serviranno delle coordinate. Incapsuliamo il tutto in una struct (definita nellapposito header thread.h):
// thread.h
#define MAX_THREADS 2
#define LEN 256
typedef struct Data
{
HWND parentWindow;
long x, y;
;HANDLE TH;
}Data;
4) nel file .CPP creiamo un array di strutture:
Data ThreadData[MAX_THREADS];
Il campo TH è lhandle al thread. Abbiamo per semplicità messo lhandle al thread dentro la struct:: la cosa può funzionare e semplifica un po il codice. Inoltre creeremo thread inizialmente sospesi, quindi ancora tutto è "fermo". Imponiamo che TH sia read-only per evitare il problemi legati alla sincronizzazione.
5) Riuniamo il tutto nel file Threads.cpp.
6) La funzione di creazione sarà chiamata nel main, dopo la creazione della finestra principale, e chiamerà più volte la funzione di creazione delle API di Windows, per cui la nostra funzione sarà:
void BuildOurThreads(HWND hWnd)
{
int i;
for (i =0; i<MAX_THREADS; i++)
{
ThreadData[i].parentWindow = hWnd;
ThreadData[i].x = 100 * rand() / RAND_MAX;
ThreadData[i].y = 100 * rand() / RAND_MAX;
ThreadData[i].TH = CreateThread(
NULL, // pointer to security attributes
0, // initial thread stack size
ThreadProc, // LPTHREAD_START_ROUTINE
lpStartAddress, // pointer to thread function
&ThreadData[i], // argument for new thread
CREATE_SUSPENDED, // creation flags
&ThreadData[i].TID// pointer to receive thread ID
);
} // end for
}
Abbiamo cioè creato un array di thread, ciascuno con una sua struct destinata a contenere i propri dati. Nulla vieterebbe che tutti i thread invece condividano una unica struttura, ma questo richiederebbe un accesso sincronizzato alla struttura.
Se usate il debugger, vedrete che TH e TID hanno valori assolutamente casuali per noi, per nulla sequenziali, generati da un apposito algoritmo del kernel.
7) Per il rilascio, banalmente; essendo TH un handle:
void ReleaseOurThreads(void)
{
int i;
for (i =0; i<MAX_THREADS; i++)
CloseHandle(ThreadData[i].TH);
}
Notiamo che CloseHandle di per sé NON termina il thread se è ancora in esecuzione: rilascia le risorse solo DOPO che il thread ha restituito il controlo al S.O. sia perché la sua funzione ha raggiunto il "return", sia perché è stato killato o Terminato (TerminateThread)
8) Creiamo ora i Timer che "sveglieranno" i due thread: per scelta progettuale scegliamo che i due thread si auto-sospendano ad ogni iterazione.
Potremmo farlo nel main poco prima della chiamata a BuildOurThreads. Potrebbe invece essere unidea aggiungere lID del timer nella struct.
Facciamolo, aggiungendo un campo alla struct e modificando la f. BuildOurThreads:
. . .
#define DELTAT 1000
. . .
for (i =0; i<MAX_THREADS; i++)
{
. . . .
ThreadData[i].timerID = SetTimer(
hWnd, // handle of window for timer messages
i+1,// our timer ID.use 1.2.. etc. DO NOT USE zero!
DELTAT, // time-out value, milliseconds
myTimerProc // address of timer procedure
);
} // end for
. . . .
Si noti leleganza che le API permettono: definiamo una unica callback per i due (o 1000) timer: un parametro ci permetterà di differenziare "a chi tocca", e sarà lei a scegliere i timer completamente in asincrono dal main!
9) La funzione myTimerProc può essere così definita:
VOID CALLBACK myTimerProc(
HWND hwnd, // handle of window for timer messages
UINT uMsg, // WM_TIMER message
UINT idEvent, // timer identifier
DWORD dwTime // current system time
)
{
int i;
for (i =0; i<MAX_THREADS; i++)
{
if (idEvent ==ThreadData[i].timerID)
ResumeThread(ThreadData[i].TH);
}
}
Confrontiamo lID che il timer ci passa, ed in base a quello, risvegliamo il task che a sua volta muoverà loggetto.
Notiamo ancora lestrema pulizia formale che API ben progettate permettono (e direi... "senza classi né oggetti!").
10) Killeremo i timer prima di rilasciare threads, modificando la funzione ReleaseOurThreads:
void ReleaseOurThreads(void)
{
int i;
for (i =0; i<MAX_THREADS; i++)
{
CloseHandle(ThreadData[i].TH);
KillTimer( ThreadData[i].parentWindow,
ThreadData[i].timerID);
}
}
11) creiamo la funzione che costituisce il corpo del thread:
DWORD WINAPI ThreadProc( LPVOID lpParameter)
{
// cast to our type:
Data * DataPtr = (Data*)lpParameter;
HANDLE th = DataPtr->TH;
int ID = DataPtr->TID;
for(;;)
{
DataPtr->x++;
DataPtr->y++;
SuspendThread(th);
}
return 0;
}
Si noti che la funzione che implementa i thread ha un loop e ciò sembra a prima vista molto strano a chi è abituato a scrivere callback, che di solito vengono chiamate da un ciclo, NON sotto il controllo del programmatore (p.es. il loop di gestione di un dialog, controllato completamente dal Windows).
Come detto, ci auto-sospendiamo. In definitiva NON arriverà mai a return 0, ma in questo poco importa.
12) Aggiungiamo ora la parte di disegno, sempre alla thread procedure, raffinando la parte che modifica le coordinate in modo adatto.
DWORD WINAPI ThreadProc( LPVOID lpParameter)
{
// cast to our type:
Data * DataPtr = (Data*)lpParameter;
RECT rt;
HANDLE th = DataPtr->TH;
int ID = DataPtr->TID;
HWND hWnd = DataPtr->parentWindow;
for(;;)
{
DataPtr->x++;
DataPtr->y++;
GetClientRect(hWnd, &rt);
if( DataPtr->x >= rt.right)
DataPtr->x = 1;
if( DataPtr->y >= rt.bottom)
DataPtr->y = 1;
InvalidateRect(hWnd, &rt, TRUE);
SuspendThread(th);
}
return 0;
}
Nella funzione per semplicità invalidiamo TUTTA la finestra, e NON è ottimizzato: andrebbero invalidati SOLO i rect "vecchi" e i nuovi rettangoli. Lasciamo al lettore.
Ci resta da vedere la funzione di disegno, Draw, chiamata dal main loop in seguito ad ogni messaggio WM_PAINT. Data labbondanza di parametri (coordinate, HWND etc..) la routine di disegno avrebbe essere implementata DENTRO la threadProc, ulteriormente migliorando la granularità della applicazione.
13) Per avere colori diversi aggiungiamo un campo HBR (brush) alla struct di ogni thread ed inzializziamoli. Avremo quindi:
void BuildOurThreads(HWND hWnd)
{
. . .
. . .
COLORREF crColor=RGB(255 * i, 0, 0); // brush color value
ThreadData[i].hBr = CreateSolidBrush(crColor);
} // end for
}
14)
void Draw(HWND hWnd)
{
int i;
PAINTSTRUCT ps;
HDC hdc;
TCHAR buf[256];
hdc = BeginPaint(hWnd, &ps);
RECT rt;
GetClientRect(hWnd, &rt);
for (i =0; i<MAX_THREADS; i++)
{
rt.left = ThreadData[i].x;
rt.top = ThreadData[i].y;
rt.right= rt.left + 100;
rt.bottom = rt.top + 100;
FrameRect(hdc, &rt, ThreadData[i].hBr);
sprintf(buf, "thread n. %d", ThreadData[i].TID);
rt.top+=20;
DrawText(hdc, buf, strlen(buf), &rt, DT_CENTER);
}
EndPaint(hWnd, &ps);
}
THREADS e PERFORMANCE
Provate ora ad alzare il tiro:
#define DELTAT 100 #define MAX_THREADS 20
e verificate nel task manager che succede. Il tempo di CPU è tutto sommato prossimo allo zero sulla mia macchina, anche se è evidente un po di flickering. Alzando a 1000 thread, si nota un 10/20% di tempo di CPU su una macchina di classe PIV 3 GHz.
Se siete in modalità debug, e alzate il numero di thread, in uscita dal programma, quando vengono rilasciati i threads, lo vedrete nel dettaglio:
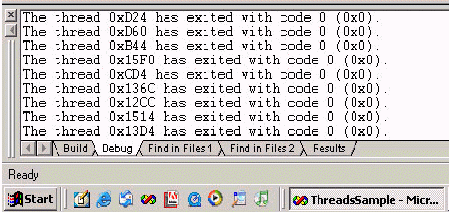
se passate a
#define DELTAT 1 #define MAX_THREADS 100
la CPU (su uno Xeon 3.2 GHz, 1 GB ram, XP 64 Bit) giunge al 50 %.
Osservazioni
Abbiamo volutamente sorvolato su alcuni aspetti architetturali nellimplementazione della soluzione.
Infatti uno dei requisiti fondamentali che Microsoft chiede ad una applicazione threadata è che il codice sia thread-safe, ossia che il codice funzioni e sia stato correttamente testato per funzionare in presenza di istanze multiple dello stesso e che laccesso ai dati comuni sia sincronizzato. Le funzioni standard ANSI C non sono thread-safe, perché usano spesso una unica copia di variabili interne per eseguire le proprie operazioni: 2 o più thread potrebbero "sporcare" a vicenda i vari buffer, come p.es. la funzione strtok o le "classiche" printf e scanf..
Ma non solo: potrebbe darsi che una funzione di libreria non sia rientrante, come già visto nellesempio console.
E allora?
Va verificato che le LIB, le DLL e tutto il software di sistema chiamato sia "thread-safe". Nellhelp ciò è specificato: per esempio per la funzione strtok():
char *strtok( char *strToken, const char *strDelimit );
Libraries
|
LIBC.LIB |
Single thread static library, retail version |
|
LIBCMT.LIB |
Multithread static library, retail version |
Nel nostro caso dobbiamo quindi modificare lelenco delle LIB/DLL che lIDE ha creato per noi nel project, linkando la libreria corretta ("link against thread-safe Libs", nella letteratura anglosassone).
Nel caso quindi che una LIB o DLL sia documentata come non-multithread, nelle opzioni del linker del progetto va rimossa e va sostituita con la sua corrispondente lib/dll multithread, e non solo per le librerie "classiche".
E inoltre fondamentale utilizzare lo switch "/MT" come nel caso dellesempio console.
CONCLUSIONI
Con questi brevi esempi, abbiamo utilizzato le principali funzioni dei thread, creazione, innesco, sospensione e terminazione. Abbiamo anche visto i timer, indispensabili strutture di Windows.
Non abbiamo visto come una applicazione può "aspettare" i singoli threads, utilizzando la funzione WaitForSingleObject(), ma questo esempio era banale e non ne aveva bisogno.
Da ultimo un grazie a "Mess", che ha rivisto con pazienza larticolo dando suggerimenti utili, anche se non sempre "graditi".
- "Operating System Concepts Seventh Edition", Avi Silberschatz, Peter Baer Galvin, Greg Gagne, John Wiley & Sons, Inc.
- API win32:
http://msdn.microsoft.com/library/default.asp?url=/library/en-us/dllproc/base/multiple_threads.asp - Threads security attributes:
http://msdn.microsoft.com/library/default.asp?url=/library/en-us/secauthz/security/security_attributes.as - Win32 System Programming Johnson Hart Addison Wesley
- Modern Operating Systems, Andrew S. Tanenbaum, Andrew Tannenbaum