INTEGRALI
Il C# fornisce nove tipi di dato integrali raggruppati nelle seguenti categorie:
| Tipo | C# |
| Intero | int e uint |
| Short | short e ushort |
| Long | long e ulong |
| Byte | byte e sbyte |
| Carattere | char |
Una variabile dichiarata con uno di questi tipi di dato, occuperà una determinata quantità di memoria. Vedremo uno per uno quanto occupano in termini di byte.
Tipo di dato INTERO
Un tipo di dato intero, int, occupa 4 bytes cioè 32 bits.
Esso può contenere un numero intero con segno compreso tra: -2.147.483.648 e 2.147.483.647 . Ma se volessimo utilizzare solo numeri senza segno, potremmo utilizzare comunque un intero ma di tipo uint.
Con un tipo uint (unsigned int), abbiamo la possibilità di rappresentare un numero compreso tra 0 e 4.294.967.295 .
Ora con un piccolo programmino, faremo la somma di due variabili intere. Copiate il sorgente nel blocco note, salvatelo nella vostra cartella con il nome di Somma.cs e compilatelo con il comando
csc /nologo Somma.cs
|
N.R. |
Codice sorgente Somma.cs |
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
// questo programma somma due interi
using System;
class Somma
{
public static void Main()
{
// dichiaro la prima variabile intera
int numero1;
// dichiaro la seconda variabile intera
int numero2;
//dichiaro la variabile intera che conterrà il risultato
int somma;
// assegno alle prime due variabili i rispettivi valori
numero1=235;
numero2=265;
/* assegno alla variable somma il risultato
dell'operazione */
somma=numero1+numero2;
// stampa il risultato
Console.WriteLine("\nLa somma = ",somma);
}
}
|
Questa è la sequenza dei comandi con il relativo risultato:
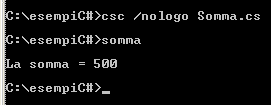
A titolo di esercizio, cambiate a vostro piacimento i valori delle variabili e ricompilate il tutto.
Tipo di dato SHORT
Il tipo di dato intero, come abbiamo visto, occupa 4 bytes di memoria, ma qualora avessimo bisogno di elaborare numeri con cifre di molto inferiori e che sicuramente non eccedono valori compresi tra -32.768 e 32767, possiamo utilizzare agevolmente il tipo di dato short. Esso infatti occupa 2 bytes cioè 16 bits di memoria consentendo un risparmio notevole di memoria. Se volessimo utilizzare solo numeri positivi, possiamo utilizzare il tipo ushort (unsigned short) che potrà contenere valori compresi tra 0 e 65.535 . Nel programmino potete sostituire il tipo int con short o ushort tenendo presente di non superare i detti limiti.
Tipo di dato LONG
Se in un programma avete invece bisogno di manipolare numeri interi molto grandi, avete bisogno di un tipo di dato capace di contenere tali numeri. A tale scopo C# mette a disposizione il tipo long (con segno) che utilizza ben 8 bytes, cioè 64 bits.
Può memorizzare un numero compreso tra:
-9.223.372.036.854.775.808 e 9.223.372.036.854.775.807
Mentre se volete utilizzare un tipo long però senza segno,
dovete utilizzare il tipo ulong (unsigned long) che può
contenere un numero compreso tra:
0 e 18.446.744.073.709.551.615 .
Quando si progetta un programma, si deve tener presente di utilizzare il giusto tipo di dato onde evitare inutili sprechi di memoria. Quindi pensate bene a quale tipo si adatti meglio all'elaborazione e al trattamento dei dati negli algoritmi del vostro programma.
Tipo di dato BYTE
Durante la progettazione di un programma può nascere l'esigenza di dover manipolare valori che hanno bisogno di un singolo byte. Il C# (come gli altri linguaggi) mette a disposizione un tipo di dato che utilizza un singolo byte, il tipo appunto byte.
Un tipo byte è compreso tra 0 e 255 (senza
segno), mentre se volessimo utilizzare numeri con segno, utilizzeremo
la versione sbyte (signed byte) i cui valori sono compresi tra:
-128 e 127.
Secondo voi, nel programma Somma.cs compare una variabile che può essere convertita in un tipo byte?
Tipo di dato CARATTERE
Oltre ai numeri potrebbe nascere la necessità di memorizzare dei caratteri. Il C# ci mette a disposizione il tipo char che ci permette di farlo. I caratteri sono lettere come A, B, C, d, g, e, o come !, $, /, ) ecc. . Il computer interpreta i caratteri come numeri seguendo uno standard chiamato UNICODE (di 2 bytes). Ogni carattere o simbolo, viene identificato con un numero intero compreso tra 0 e 65.535. All'interno di un progamma per poter assegnare un carattere ad una variabile, bisogna metterlo tra apici singoli, esempio:
// dichiaro una variabile di tipo char
char car;
// le assegno il carattere a
car='a';
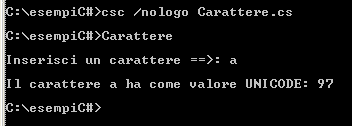
Faremo girare ora un programmino che converte un carattere digitato da tastiera nel corrispondente valore UNICODE.
|
N.R. |
Codice sorgente Somma.cs |
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
// programma che visualizza il corrispondente valore UNICODE
// del carattere inserito da tastiera
using System;
class Carattere
{
public static void Main(string[] args)
{
// dichiaro una variabile char
char car;
// visualizzo un messaggio
Console.Write("\nInserisci un carattere ==>: ");
// leggo da tastiera un carattere
car=(char) Console.Read();
// stampo il valore del carattere
Console.WriteLine("\nIl carattere {0} ha come valore UNICODE: {1}",car,(int)car);
/* il valore {0} si riferisce alla prima variabile cioè car
il valore {1} si riferisce invece alla successiva cioe' (int) car
*/
}
}
|
Nel codice del listato, sono state introdotte alcune novità la prima delle quali è listruzione alla riga 13:
car=(char) Console.Read();
Essa fa uso della funzione (metodo) Read() delloggetto Console che ci permette di leggere un carattere digitato dalla tastiera. Il carattere letto, però, viene interpretato dal computer come un numero intero a 16 bits che in realtà è proprio il codice UNICODE che noi stiamo cercando. Purtroppo per incompatibilità di tipo, non possiamo attribuire ad una variabile di tipo carattere un numero intero. Quindi listruzione è preceduta dal costrutto (char).
Questo costrutto è definito con una parola un po caustica: casting. Il casting impone una conversione esplicita di un tipo di dato in un altro. Nel caso dellistruzione di riga 13, il codice numerico letto da tastiera (UNICODE), viene convertito nel suo carattere corrispondente e assegnato alla variabile car.
La seconda novità riguarda le istruzioni di stampa. Avete notato, nelle istruzioni di riga 11 e di riga 15, compare questa sequenza di caratteri: \n . Non sono caratteri stampabili ma sono caratteri di controllo che indicano al sistema semplicamente di andare a capo prima di visualizzare il messaggio. Di queste sequenze ne esistono svariati tipi e ci consentono di formattare meglio tutto ciò che dovrà essere visualizzato. Man mano che si presenterà loccasione, ne spiegherò altri.
La terza ed ultima novità riguarda sempre le istruzioni di stampa in particolare il posizionamento e scelta delle variabili da stampare nel mezzo di una stringa che rappresenta un messaggio.
La definizione è un po articolata quindi lo vediamo in pratica.
Listruzione della riga 15

consente di effettuare una stampa un po particolare.
Potete notare che allinterno della funzione (metodo) WriteLine compaiono delle coppie di parentesi graffe con un numero. Questo numero è un indice e si riferisce, in sequenza, agli argomenti che compaiono dopo il messaggio incluso nei doppi apici. Tali argomenti altro non sono che le variabili da stampare; per la precisione, come si vede dallo schema, lindice {0} si riferisce alla variabile car che verrà visualizzata proprio lì dove compare lindice. Lo stesso ragionamento vale per la successiva coppia di parentesi graffe. In generale, se abbiamo n variabili da visualizzare, utilizzeremo n coppie di parentesi graffe, posizionandole dove più ci interessa, con indice che va da 0 a n-1. Un ultima considerazione riguarda il casting utilizzato per stampare il codice UNICODE del carattere. Per visualizzare lesatto codice del carattere letto, dobbiamo effettuare loperazione inversa della riga 13, cioè trasformare il carattere nel suo corrispondente codice tramite appunto il casting.
Questa è la sequenza della compilazione ed il risultato generato da programma:
Numeri in virgola mobile
Nelle nostre applicazioni, avremo sicuramente bisogno di manipolare, oltre ai numeri interi, anche numeri che hanno una parte decimale. Per esempio, se abbiamo bisogno di fare calcoli scientifici, è indispensabile utilizzare variabili numeriche che ci permettono di memorizzare numeri con la virgola. Il C# ci mette a disposizione due tipi numerici in virgola mobile:
float e double
float è il primo tipo di dato che viene utilizzato per la memorizzazione di numeri con la virgola. Archivia un numero in 4 bytes di memoria ed è compreso tra:
1,5 x 10-45 e 3,4 x 1038 .
Esso ha una precisione di circa 7 cifre e per utilizzarlo, bisogna farlo seguire dal suffisso f o F, esempio:
float x = 3.5F;
Se non si utilizza il suffisso nella precedente dichiarazione, viene generato un errore di compilazione, in quanto si tenta di memorizzare un valore double in una variabile float.
double è il secondo tipo di dato. Archivia numeri in 8 bytes di memoria e quindi, rispetto al tipo float, sono molto più grandi e precisi. Un double è compreso tra:
5,0 x 10-324 e 1,7 x 10308
con una precisione di circa 15 o 16 cifre.
Il C# fornisce un tipo di dato che ci consente di memorizzare numeri con grande precisione: il tipo decimal. Esso denota un tipo di dati a 128 bit. Rispetto ai tipi a virgola mobile, il tipo decimal è caratterizzato da una maggiore precisione e da un intervallo ridotto, che lo rende adatto a calcoli finanziari e monetari. Un numero di tipo decimal è compreso approssimativamente tra:
±1.0 × 10−28 e ±7.9 × 1028
con una precisione di 28-29 cifre significative.
Se si desidera che un valore numerico reale venga gestito come decimal, utilizzare il suffisso m o M, ad esempio:
decimal saldo = 3579.5m;
Senza il suffisso m, il numero viene infatti gestito come valore double, e questo provoca un errore di compilazione.
TIPO BOOLEANO
A volte ci interessa sapere se un elemento è vero o falso. Questo tipo utilizza 1 byte di memoria e la sua sintassi è molto semplice, per esempio:
bool flag=true;
ho dichiarato una variabile di tipo bool e le ho assegano il valore true (vero). Questa variabile la potrei utilizzare come segnalatore (flag) dell'esito di una qualche elaborazione testandone il contenuto cioè true o false.
In queste prime lezioni, abbiamo parlato di variabili cioè elementi che utilizziamo per memorizzare un valore che può cambiare durante una elaborazione. Ma, come in tutti i linguaggi di programmazione, esistono anche degli elementi che ci consentono di archiviare un valore che non cambierà mai: le costanti. La sintassi è:
const tipo nomevariabile;
esempio
const float PIgreco=3.14F;
con le costanti siamo sicuri di utilizzare un valore che non potrà mai cambiare durante la vita di una applicazione.
Nella prossima lezione parleremo degli operatori.